MOUNTAIN VIEW / MÜNCHEN (IT BOLTWISE) – Die Fähigkeit von VideoPoet, Videos mit vielfältigen Bewegungen und Stilen zu erzeugen, die auf spezifische Texteingaben zugeschnitten sind, zeigt sein fortgeschrittenes Verständnis von Inhalt und Kontext.
Die Welt der Videogenerierung hat einen neuen Meilenstein erreicht. Google AI präsentierte kürzlich VideoPoet, eine revolutionäre Methode, die jedes autoregressive Sprachmodell oder Großes Sprachmodell (LLM) in einen hochwertigen Videogenerator verwandeln kann. Diese Innovation demonstriert Spitzenleistungen in der Videoproduktion, insbesondere bei der Erzeugung einer breiten Palette von großen, interessanten und hochauflösenden Bewegungen.
Im Kern ist VideoPoet ein Multitasking-Wunderwerk. Es kann statische Bilder animieren, Videos für Inpainting oder Outpainting bearbeiten und sogar Audio aus Videos generieren. Seine Fähigkeit, Texte, Bilder oder Videos als Eingaben zu nehmen und Ausgaben in Form von Text-zu-Video, Bild-zu-Video und Video-zu-Audio-Umwandlungen zu liefern, unterstreicht seine Vielseitigkeit als umfassende Lösung für diverse Videoerstellungsaufgaben. Ein wesentlicher Vorteil ist, dass mehrere Funktionen in einem einzigen Modell integriert sind, wodurch separate spezialisierte Komponenten überflüssig werden.
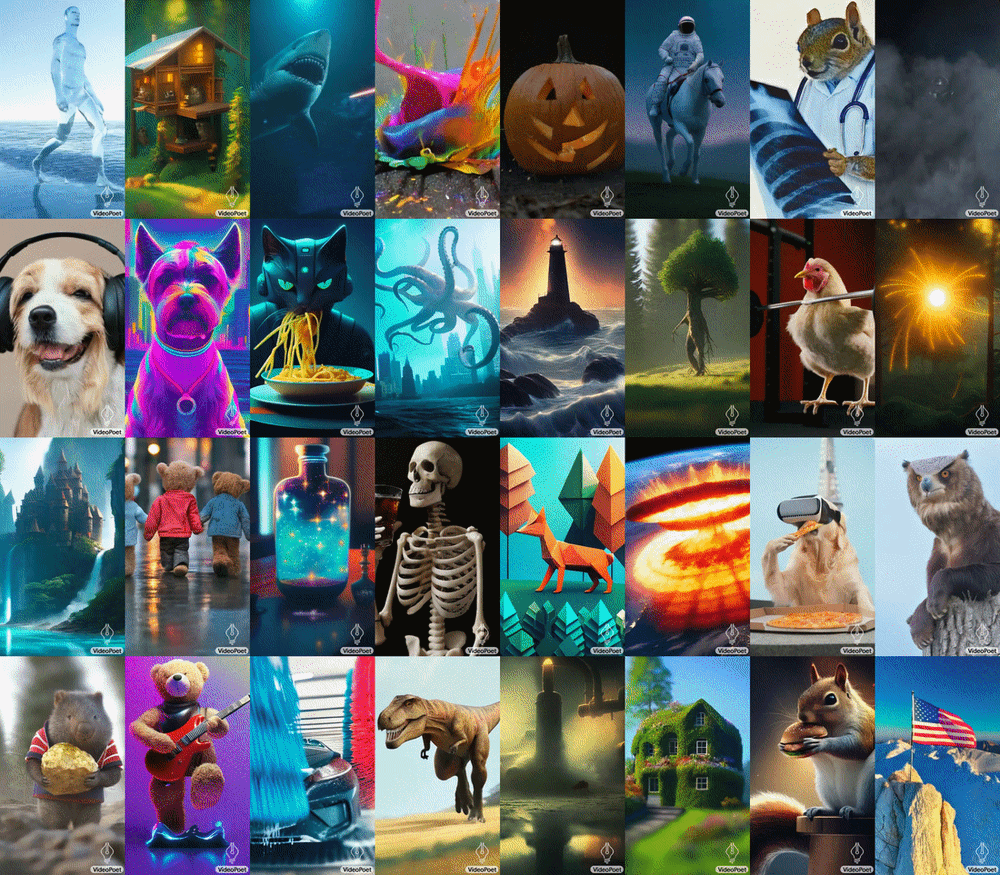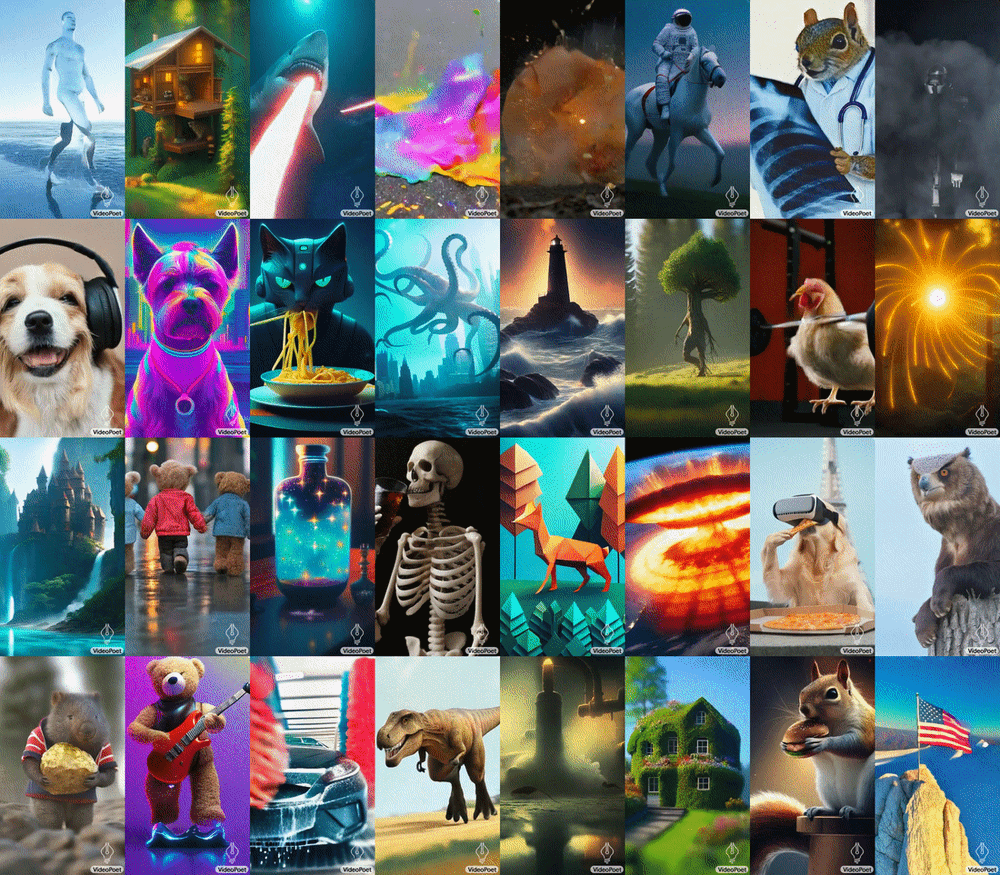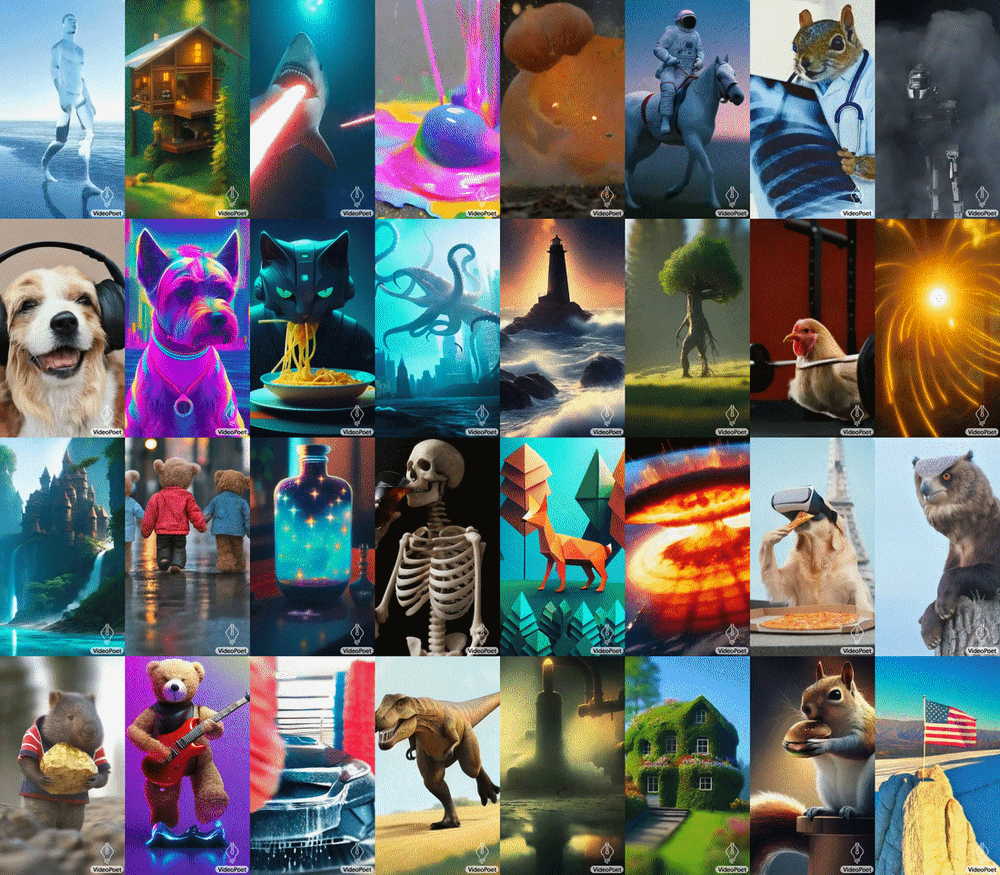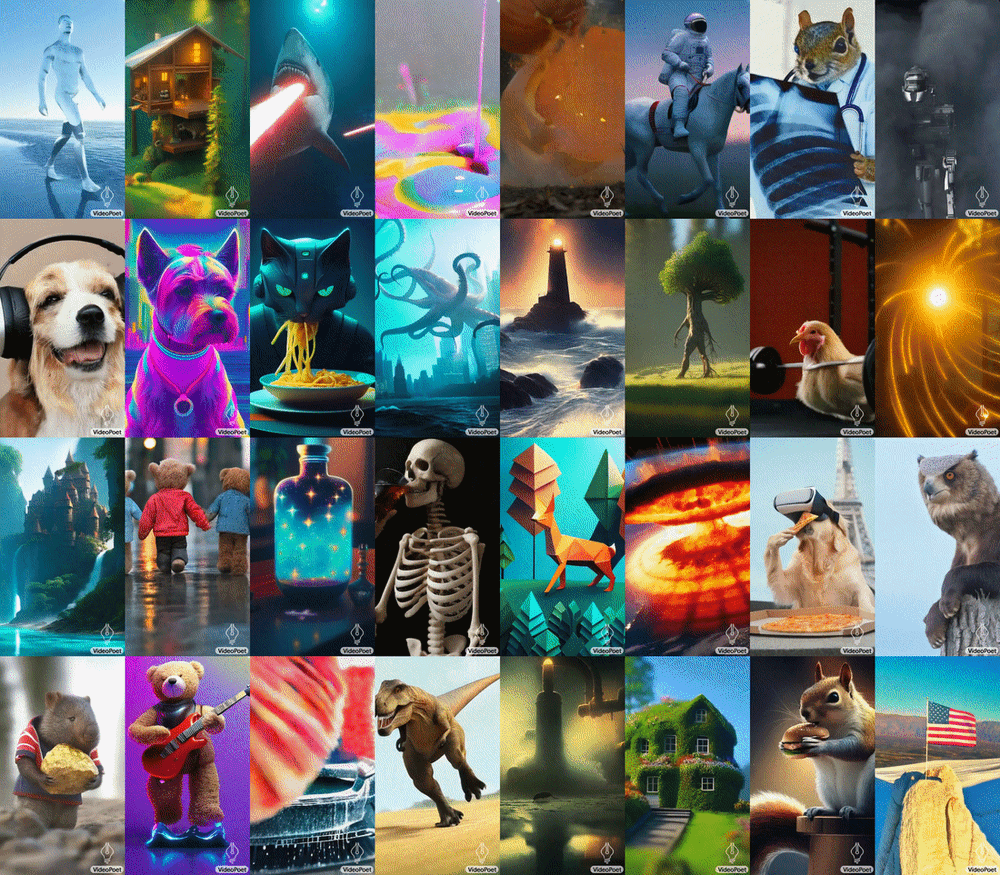
VideoPoet hebt sich durch seine Verwendung von diskreten Token für die Video- und Audiorepräsentation ab, ähnlich wie LLMs Sprache verarbeiten. Mit Hilfe mehrerer Tokenizer (MAGVIT V2 für Video und Bild, SoundStream für Audio) kann VideoPoet diese Modalitäten in ein sichtbares Format kodieren und dekodieren. Diese Methode ermöglicht es dem Modell, seine Sprachverarbeitungsfähigkeiten auf Video und Audio auszuweiten, was es zu einem robusten Werkzeug für Kreative und Technologen macht.
Die Fähigkeit von VideoPoet, Videos mit vielfältigen Bewegungen und Stilen zu generieren, die auf spezifische Texteingaben zugeschnitten sind, zeigt sein fortgeschrittenes Verständnis von Inhalt und Kontext. Ob es darum geht, ein Gemälde zu animieren oder einen Videoclip aus einem beschreibenden Text zu erzeugen, das Modell demonstriert eine bemerkenswerte Fähigkeit, die Integrität und das Aussehen von Objekten auch über längere Zeiträume hinweg zu bewahren. Google weist darauf hin, dass das Modell Videos sowohl im quadratischen Format als auch im Hochformat generieren kann, um Generationen auf kurzformatige Inhalte zuzuschneiden, und unterstützt auch die Audioerzeugung aus einem Videoeingang.
Eine bemerkenswerte Funktion von VideoPoet ist seine interaktive Videobearbeitungsfähigkeit. Nutzer können das Modell anleiten, Bewegungen oder Aktionen innerhalb eines Videos zu modifizieren, was einen hohen Grad an kreativer Kontrolle bietet. Das Modell kann auch präzise auf Kamerabewegungsbefehle reagieren und seine Nützlichkeit bei der Erstellung dynamischer und visuell ansprechender Inhalte weiter steigern. Darüber hinaus kann VideoPoet auch glaubhafte Audioinhalte für generierte Videos ohne jegliche Anleitung erzeugen und zeigt damit sein hervorragendes multimodales Verständnis.

Standardmäßig erzeugt VideoPoet 2-Sekunden-Videos. Bei einem 1-Sekunden-Video-Clip kann das Modell jedoch 1 Sekunde Videomaterial vorhersagen. Dieser Prozess kann unbegrenzt wiederholt werden, um ein Video beliebiger Dauer zu produzieren.
Obwohl die Ergebnisse noch deutlich hinter den Werkzeugen von Runway und Pika zurückbleiben, unterstreicht VideoPoet die wichtigen Fortschritte, die Google bei der KI-basierten Videogenerierung und -bearbeitung macht.

- Die besten Bücher rund um KI & Robotik!

- Die besten KI-News kostenlos per eMail erhalten!
- Zur Startseite von IT BOLTWISE® für aktuelle KI-News!
- IT BOLTWISE® kostenlos auf Patreon unterstützen!
- Aktuelle KI-Jobs auf StepStone finden und bewerben!
Stellenangebote
KI Manager Technologie (m/w/d)
Werkstudent politisches und KI-basiertes Monitoring (m/w/d)
KI Entwickler (m/w/d)
Data Engineer im KI Team (m/w/d)



- Künstliche Intelligenz: Dem Menschen überlegen – wie KI uns rettet und bedroht | Der Neurowissenschaftler, Psychiater und SPIEGEL-Bestsellerautor von »Digitale Demenz«


- Krauss, Patrick(Autor)



Du hast einen wertvollen Beitrag oder Kommentar zum Artikel "Google AI stellt VideoPoet vor: Ein Zero-Shot-Video-Generierungsmodell für Große Sprachmodelle" für unsere Leser?
 #Sophos
#Sophos
Es werden alle Kommentare moderiert!
Für eine offene Diskussion behalten wir uns vor, jeden Kommentar zu löschen, der nicht direkt auf das Thema abzielt oder nur den Zweck hat, Leser oder Autoren herabzuwürdigen.
Wir möchten, dass respektvoll miteinander kommuniziert wird, so als ob die Diskussion mit real anwesenden Personen geführt wird. Dies machen wir für den Großteil unserer Leser, der sachlich und konstruktiv über ein Thema sprechen möchte.
Du willst nichts verpassen?
Du möchtest über ähnliche News und Beiträge wie "Google AI stellt VideoPoet vor: Ein Zero-Shot-Video-Generierungsmodell für Große Sprachmodelle" informiert werden? Neben der E-Mail-Benachrichtigung habt ihr auch die Möglichkeit, den Feed dieses Beitrags zu abonnieren. Wer natürlich alles lesen möchte, der sollte den RSS-Hauptfeed oder IT BOLTWISE® bei Google News wie auch bei Bing News abonnieren.
Nutze die Google-Suchmaschine für eine weitere Themenrecherche: »Google AI stellt VideoPoet vor: Ein Zero-Shot-Video-Generierungsmodell für Große Sprachmodelle« bei Google Deutschland suchen, bei Bing oder Google News!